产品介绍:
NSX:
来自 VMware 在 2012 年收购的 SDN 鼻祖公司 Nicira,现在已经是非常成熟的解决方案了,有广泛的客户在生产环境中使用。
NSX 可以打通物理网络的孤岛,抽象出网元,通过转控分离的 SDN 架构实现一致的网络功能,甚至打通多中心、多云环境,实现整个虚拟网络在多云、多中心一致的网络和安全策略。现在它可以针对容器环境实现 Pod 层面的全网可路由、为特定应用确定固定的 IP 地址段、并将安全微分段细化到 Pod 层面。
Avi:
Avi 的正式名称是 NSX Advanced Load Balancer(简称为 NSX-ALB),它来自 VMware 于 2019 年收购的纯软件 ADC(应用交付控制器,俗称负载均衡)公司——Avi Networks,因此我们一般俗称这个产品叫做 Avi。
和 NSX 一样,Avi 同样采用了基于 SDN 的转控分离的架构,配置和部署就变得非常简单,且能实现资源池,有很好的弹性以及自愈的架构,消除了竖井式的 ADC 架构。它还自带 GSLB(广域网负载均衡)、WAF(Web 应用防火墙)、多租户、应用可视化与分析等诸多丰富的功能。针对容器环境,还能同时实现容器 ingress(入向路由)、服务暴露。
在介绍 VMware NSX+Avi 的产品组合是如何打通从 CI 到 CD 的“最后一公里”之前,我们首先来谈一谈什么是 CI、CD,以及为什么从 CI 到 CD 阶段是存在潜在的障碍和瓶颈的。
什么是 CI、CD
如今,越来越多的企业用户会将开发环境转向容器。这是因为在以往,我们在应用开发阶段一般会使用“瀑布式开发”的模型。瀑布式开发意味着应用的代码设计阶段将占到整个应用开发的生命周期的一半以上,并且由于其单体式、紧耦合的架构,会将框架锁定,之后如果需求变更,就很难修改,可能需要从头改到尾。这就意味着,现在的企业在需要随时提升 end user 体验、处理 bug,从而快速实现版本迭代的背景下,瀑布式开发就不会再流行了。因此人们需要实现敏捷开发,用松耦合的方式来实现代码架构。换句话说,人们现在会将大的代码框架分成了多个模块或多个服务,一旦需求有变更,只会对一个模块或服务进行修改,这就规避了瀑布式模型下牵一发而动全身的弊端。敏捷开发的应用也被称为“敏态应用”。代码的开发、运维、bug 处理、新版本上线与老版本下线等,将实现一体化。人们常常将这个过程称为 DevOps,在这样的技术趋势下,我们的服务创建时间、应用的生命周期将会是秒级,将实现 100% 的自动化,应用是微服务的架构,底层则是通过容器、K8S 搭建的 PaaS 和 CaaS 平台。我们将这样的新型应用的模型,称为现代化应用“Modern Application”。
通俗的说,CI(Continuous Integration,持续集成)就是将开发代码打包成容器镜像的过程。
由于大的应用框架被切割成了多个“微服务”,就需要有一套机制,持续地集成多组开发人员维护着的且需要频繁上线、迭代的代码,如自动构建应用并运行不同级别的自动化测试来验证这些更改,确保这些更改没有对应用造成破坏。这意味着测试内容涵盖了从类和函数到构成整个应用的不同模块。如果自动化测试发现新代码和现有代码之间存在冲突,CI 可以轻松地快速修复这些错误。
对于 CD,最初的写法是 Continuous Deployment,直译是持续部署。但现今,更多业内人士认为写法应当是 Continuous Delivery,直译是持续交付。因为 CI 之后,代码已经被打包成了容器镜像,我们需要部署在 K8S 环境中,实现服务的治理和调度。但我们开发应用是为了让外部的用户去访问并使用,因此光部署还不够,还需要灵活、智能、快速、安全地交付出去。
持续部署意味着开发人员对应用的更改应该在编写后立即就能生效(假设它通过了自动化测试)。在 K8S 环境部署完毕并生效的代码,再如何持续交付出去,首先需要服务暴露、入向路由的机制,让外部看得懂容器化环境里的应用并能访问。再者,由于现在代码开发基本上是基于 Http/Https 协议的 Web 应用,因此负载均衡、针对终端类型的选择、网页的优化、图片的压缩、连接的加速、页面缓存、会话保持、网络和 Web 安全等,都是需要考虑的问题,这些都是开发者特别关心的。这样也更加便于持续接收和整合来自用户端的反馈,反过来进行 CI 的代码迭代。CI 与 CD 将成为一个闭环的生命周期。
那么为什么从 CI 到 CD 的“最后一公里”存在障碍,没有打通呢?
网络,网络,还是网络!重要的事情说三遍!
首先是容器底层网络。容器化的应用中,各个微服务不关心底层 IP,但是 IP 客观存在,且随时可能因为服务版本的更迭而变化,也随时可能因为遇到突发流量而扩展。我们需要将这些服务不关心,但客观存在的各 Pod 的 IP 地址互联互通起来,但 Pod 的 IP 地址经常变动且经常扩展,传统网络的路由和交换协议就不适用了。K8S 容器接口 CNI 的标准,就是为了实现 Pod 互连而提出的。开源的 CNI 实现主要是 Flannel 和 Calico。
本文不会探讨 Flannel 和 Calico 的实现原理和技术细节,我们直接来看它们存在哪些问题。
Flannel 主要实现二层交换功能,它存在的问题有:
- 不支持 pod 之间的网络隔离。Flannel 设计思想是将所有的 pod 都放在一个大的二层网络中,所以 pod 之间没有隔离策略。简单来说,就是 Flannel 无法实现任何网络安全功能。
-
组件复杂,效率不高。Flannel 模型下有三种组件(Cni0、Flannel1、Flanneld),流量经过多种组件的封装、解析,势必会造成传输效率的下降。简单来说,就是每一次二层通讯都需要多次网络地址转换(NAT),效率可想而知。
Calico 主要实现三层路由功能,它存在的问题有:
- 无多租户功能。
Calico 的设计思路是将 K8S 的 host 当作路由器,其三层方案是直接在 host 上进行路由寻址,那么对于多租户就面临地址冲突的问题。
- 路由规模问题。
我们刚才就说过了,Calico 的设计思路是将 K8S 的 host 当作路由器,因此 Calico 的路由规模和 Pod 分布有关,如果 Pod 离散分布在不同 host 中,势必会产生海量的路由项。实现这样的路由,还得配置 BGP 这种复杂的运营商级别的路由协议。
- iptables 规则和规模问题:
一台 host 上可能存在十几甚至几十个容器实例,这样一来,过多的 iptables 规则就造成了复杂性和不可调试性,同时也存在性能损耗。
- 跨子网时的网关路由问题:
当对端网络不可达,需要通过三层路由器时,就需要网关支持自定义路由配置,即 Pod 的目的地址为本网段的网关地址,再由网关进行跨三层转发。这就需要网络部门的介入,修改底层物理路由器或物理核心交换机的配置,开发人员是无法自主在容器化环境内部实现网络的全定义的。
- 有简单的容器内部网络安全功能,但是需要根据 Namespace 来定义,且遇到 IP 地址变化或扩展时,很难自动变更安全策略,需要手动调整。
以上是 Flannel 和 Calico 技术本身的限制。还有很多企业客户关心的问题,它们的组合同样不能实现:
- 系统部门希望虚拟化环境和容器环境能有一致的网络和安全策略。
-
外部有流量分析设备,或者说叫 NPM。企业客户希望这些设备为一些特定的 Pod 的 IP 地址进行持续的流量监控、安全监控。
-
Web 和 App 容器化了,但是有统一的数据库服务器在容器化环境外部。哪些 Pod 能访问外部数据库,哪些不能访问,是完全无法定义的。
-
无支持。出了问题只能百度搜,或者向经验更加丰富的程序员朋友求救。
这个阶段还没到 CD 的 Continuous Delivery 阶段呢,还在 Continuous Deployment 阶段,我们网络上就遇到了这么多的问题。我们的应用在持续的上线和版本迭代过程中,如果部署时网络存在这么多潜在的问题,包括管理问题、效率、安全性、自动化等,CI 到 CD 能顺畅吗?
我们再看针对 Continuous Delivery 阶段的应用服务网络。通常的实现方法是外部 ADC(通称负载均衡器,本文后面都会用 ADC 来代称)和开源的组合方案来实现,比较典型的组合是 F5+Nginx,也有如 Openshift 中容器内部使用 HA Proxy 配合外部的 HA Proxy 来实现。这种实现方式是 Nginx 或 HA Proxy 将自己的反向代理实例在 Node 里充当一个 Pod 来实现入向路由,使得外部 ADC 能通过它们识别 Pod 的服务,这是服务暴露到外部的过程,再由外部 ADC 实现针对这些服务的负载均衡和其它高级应用交付功能。它存在的问题有:
- 路径不优化。
外部 ADC 需要随机找到一个 Nginx 或 HA Proxy 的 Pod,然后 Nginx 或 HA Proxy 再通过内部的选择机制,找到最优的服务提供给访问者,流量需要两层寻址,效率不佳,且多了一层故障点,出了问题可能会造成网络部门、infra部门和开发部门互相推卸责任,排错还依赖复杂的 tcpdump 抓包。
- 资源池无法实现。
云化环境中,外部的 ADC 使用硬件已不再合适,但是传统 ADC 厂商的软件和其硬件几乎没什么区别,尤其是目前还没有任何一家传统 ADC 厂商能在其软件 ADC 上实现 vMotion、HA、DRS 等功能,这就意味着传统 ADC 的软件出了问题或遇到资源不足时迁移不走,这就仍然是竖井式、烟囱式的架构,无法实现资源池,也无法灵活调度资源,更无法实现自动化。我们为什么要从小型机转向虚拟化,为什么要从磁盘阵列转向超融合,相信读者都是清楚的——这就是为了消除竖井式的服务器、竖井式的存储架构,并实现资源池。传统 ADC 厂商的在云化环境中的软件版本,仍然走了竖井式、烟囱式的架构的老路。
- 性能问题。
由于 Nginx 和 HA Proxy 都是自己作为 Pod 安装在 K8S 集群内部,这样会消耗 K8S 集群性能,能扩展的 Pod 就会变少,K8S 集群整体性能和扩展性都会受到影响。
- 应用可视化问题。
可视化是 CD 阶段的一个重要功能,因为通过可视化,可以实现应用性能分析、归属地来源和终端分析、安全事件分析等,并根据分析结果促进 DevOps。容器内部的 Prometheus 和 Grafana 能看到的是东西向服务的可视化,但 CD 的 Continuous Delivery 阶段主要是针对南北向的访问请求。这就需要在 ADC 上实现对用户终端访问容器内部时的可视化。ADC 和 Nginx 其实都可以将 log 吐给开源的 ELK 来实现,但因为运维能力,除了互联网行业,没有多少企业客户能真正将 ELK 用好,并且出了问题是没有厂商支持的。并且吐 log 有一个时间过程,就意味着可视化是非实时的。
- 多租户和权限管理问题。
一般来说,外部的 ADC 都是网络部门在管理,但是现在的应用开发模型下,应用开发者随时可能上线新应用、新版本,每一次微小的版本变更,可能都需要网络部门在外部 ADC 做负载均衡策略、优化策略的变更,难道每一次变更都要跨部门开个会,或者提个工单吗?每个项目开发组,都希望能自主式变更 ADC 策略并持续交付出去,但是不仅多租户没有解决,还无法得到网络部门的设备管理和配置权限,Continuous Delivery 阶段势必阻碍重重。
- 配置习惯问题。
就算应用开发者拿到了外部 ADC 的管理员账号和密码,但开发者习惯通过 Linux、yaml 文件来进行配置和管理,这和网络管理员用 cli 命令行、图形化界面来管理和运维的设备的配置习惯完全不同。对于开发者来说,这样的配置模式会感到非常别扭,还是很难自主定义外部 ADC 策略。
- 如果使用免费版 Nginx 或 HA Proxy 实现服务暴露、入向路由,出了问题同样没有支持。
为了解决从 CI 到 CD 的“最后一公里”问题,VMware 大中华区 VCN(Virtual Cloud Networking,虚拟云网络)团队打造了“现代化应用连接”解决方案。
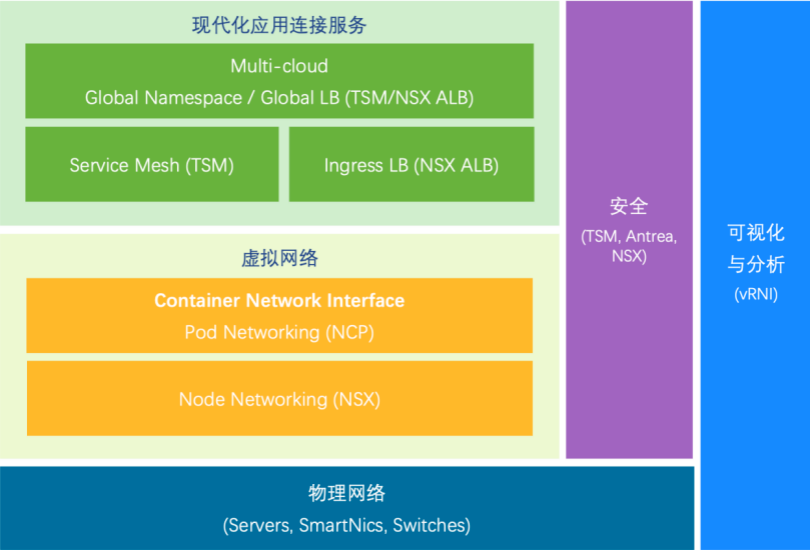
该方案包括:
NSX——虚拟网络与容器 CNI 网络的整合
VMware NSX 可以打通物理网络的孤岛,抽象出网元,通过转控分离的 SDN 架构实现一致的网络功能,甚至打通多中心、多云环境,实现整个虚拟网络跨多云、多中心的一致的网络和安全策略。针对容器网络接口 CNI,NSX 的解决方案叫 NCP,全称是 NSX Container Plugin。其实现是将 NSX 的一个插件嵌在容器的 Node 里,由其提取可能随时变化的 Pod 信息交给 NSX 控制器再由 NSX 的数据平面实现全网的路由和交换以及安全功能。这样做的好处有:
- 利用了 NSX 的分布式路由、分布式交换、分布式防火墙功能,实现全网 Pod 可路由和精细颗粒度的安全策略,且 Flannel 和 Calico 的弊端全部一扫而空,无论是复杂配置,还是性能、路由表问题(因为可以在本地找到下沉后的分布式网关和匹配安全策略)。
-
可以为一些租户、一些专门的应用集群分配专门的固定地址段,这个地址段能被外部的物理防火墙等安全设备或流量分析设备所识别,这就解决了无外部流量可视化、访问外部数据库时策略无法书写问题。
-
虚拟机和容器 Pod 网络之间网络策略一致性、安全策略一致性也得到解决。一套管理和控制平面,VM 网络和 Pod 网络全部搞定。
现在,VMware 正在主导一个开源 CNI 项目 Antrea。未来,我们会逐渐将 NCP 的功能转向 Antrea 的商业版中,但不会发生额外的 license 费用,NSX 较高级的版本中会含 Antrea 商业版。
Avi——创新的服务暴露、入向路由、负载均衡方式
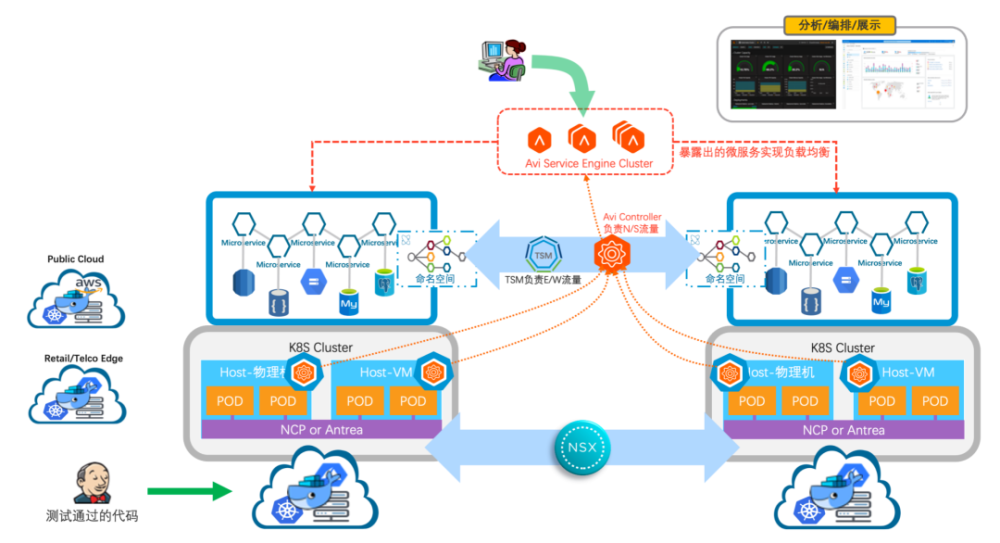
Avi 首先使用了基于 SDN 的转控分离的架构,配置和部署就变得非常简单且能实现资源池,有很好的弹性以及自愈的架构,这就解决了我之前提到的竖井式 ADC 架构问题。此外,对于容器的入向路由,Avi 的做法是将 AKO(Avi K8S Operator)或 AMKO(Avi Muti K8S Operator)以插件的形式部署在 K8S Node 内(是不是和 NCP 的实现很像)。如上图所示,AKO 或 AMKO 提取各种 Pod 信息,告诉 Avi 控制器,再由控制器自动下发配置给Avi的可灵活调度、按需扩展的资源池形式存在的转发平面 SE(Service Engine)。这样带来的优势有:
- 扁平架构,流量无需两层选路就能直接找到最优的 Pod 供 End User 访问,也不会遇到各部门踢皮球、定位问题困难、排错过程复杂等问题。
-
因为是插件部署,解决了性能问题。AKO 和 AMKO 不像 Nginx 和 HA Proxy 需要自己充当 Pod,没有 K8S 集群内部的性能损耗。
-
Avi 控制器和 Service Engine 集群又是部署在 K8S 集群外部的,能实现资源池、按需扩容、灵活的资源调度、业务无缝迁移,充分发挥了云化环境资源池的威力。
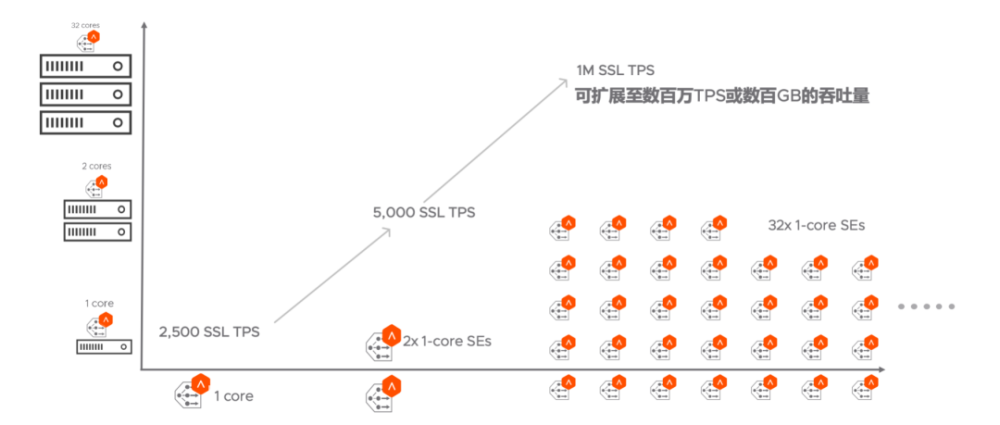
- 多租户和 RBAC(基于角色的访问控制):天生实现多租户,每个开发项目组对应的负载均衡池都是隔离状态,且都可以在 RBAC 的机制下,针对自己的负载均衡池实现自主配置,遇到服务的版本迭代和新应用的上线需要调整外部 ADC 配置时(尤其是频繁迭代时),无需向网路部门寻求帮助,真正做到从 CI 到 CD 的无缝衔接。当多租户和 NSX 网络微分段隔离功能相结合,会得到更加不一般的体验。
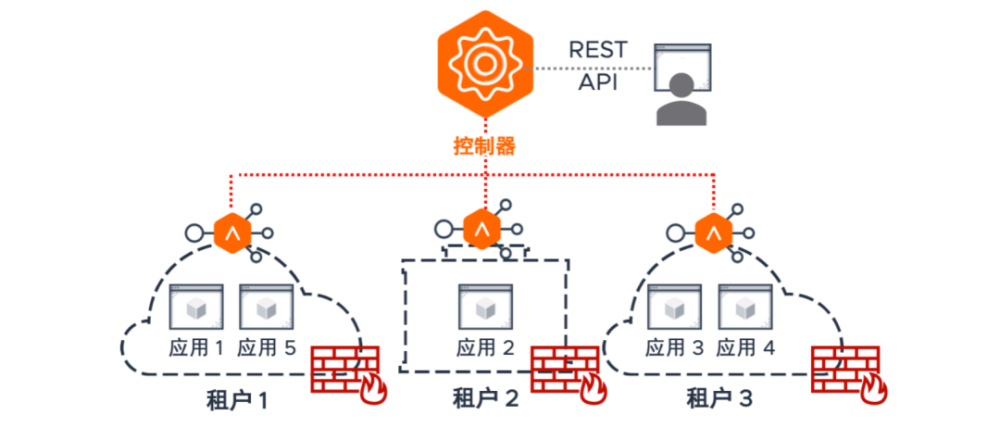
- 适合应用开发者的管理模式:通过多租户和 RBAC 获得管理权限后,开发者可以在 AKO 中通过配置 yaml 文件来提取 Pod 信息,交给 Avi 控制器并能实现自动化的配置变化以及策略下发(下发到SE集群的数据平面)。
-
DNS 和 GSLB(全局负载均衡)功能(无额外费用),每个项目组同样可以在 Avi 控制器上直接对外部 DNS 进行配置和管理,保障发布出去的业务能实现通过智能的域名访问。
-
自带 WAF 功能(无额外费用),一般暴露出来的服务很多都是 Web 服务,Avi 就可以通过 WAF 来保护它们,如防止网页篡改、针对网页的 DDoS 防护等。
-
Avi 现在甚至可以被 NSX 控制器管理和控制,这就意味着,整套现代化应用连接平台的解决方案,从 VM、Node 网络,到 Pod 互连,到服务暴露和入向路由、负载均衡,都是可以统一管理的。
-
内置的应用可视化和分析模块(无额外费用)。甚至能取代一些专业 APM 厂商提供的功能,如每个服务的延时、分析安全事件、分析终端类型和地理位置、智能排错等。这样反过来能增强 DevOps 的能力,甚至可以根据分析结果自动化完成配置修改、按需扩容或调度资源。话不多说,上图。
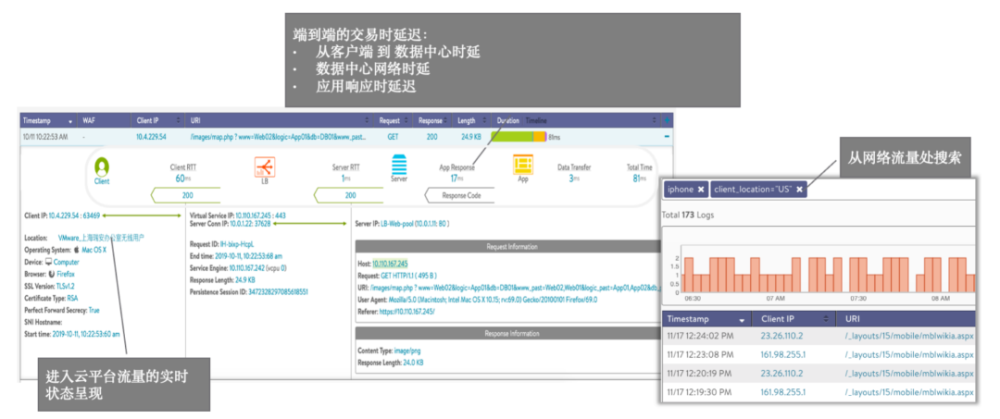
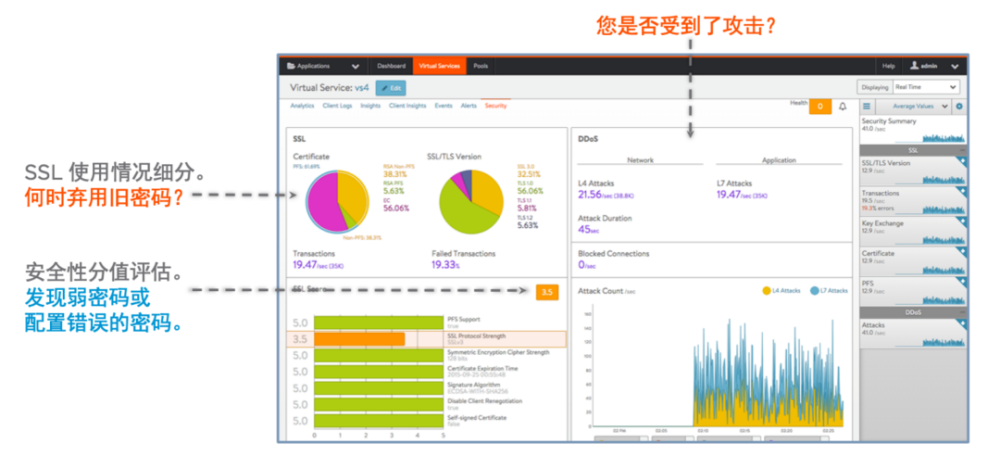
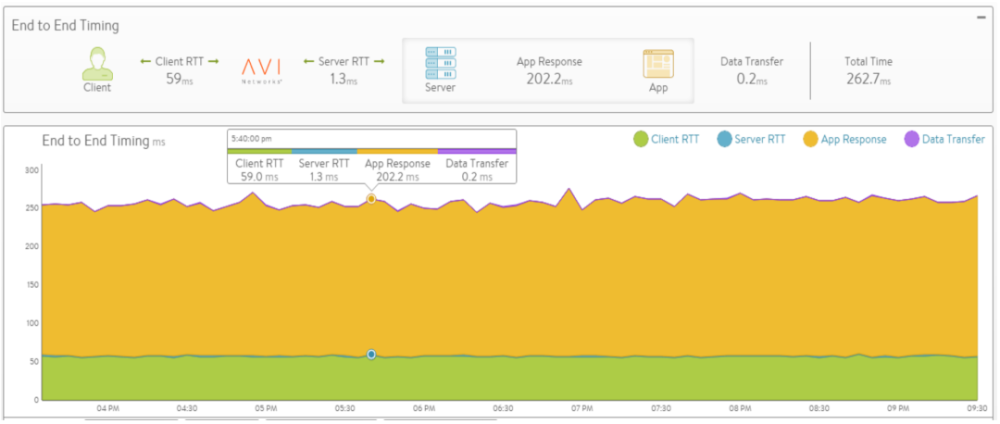
总结
至此,从 CI 到 CD 的“最后一公里”问题,已全部解决。
作者 | 范恂毅
14 年 IT 行业经验
持有安全、语音、数据中心三个方向
CCIE 认证
曾在 F5、Nutanix 等知名 IT 公司担任技术顾问
现任 VMware 大中华区 Avi 产品经理
负责 VMware 应用交付业务的推广和销售工作
-END-